Measuring the Center: Mean, Median, and Mode Explained
Learn how to calculate and choose between mean, median, and mode — key measures of central tendency in statistics and machine learning, with Python code and visual examples.
Before analyzing how your data spreads, it’s essential to understand how to measure its center. This post introduces the three most important measures of central tendency — mean, median, and mode — with examples, Python code, and practical advice for data science and machine learning.
📚 This post is part of the "Intro to Statistics" series
🔙 Previously: How to Build Frequency Tables in Python
🎯 What is Central Tendency?
Central tendency describes the “middle” or typical value in a dataset. The three main measures are:
- Mode
- Median
- Mean
Each one tells us something slightly different.
🧮 Mode
- The most frequent value in a dataset
- Works with any type of variable
- Especially useful for nominal (categorical) data
💡 Example:
If most students choose “Math” as their favorite subject, then:
Mode = “Math”
🛑 You can’t calculate a mean or median for categories like “Math” or “History” — but you can find the mode.
Tip:
A dataset can have more than one mode (bi modal or multi modal), or no mode at all if all values occur with the same frequency.
For continuous numeric data, the mode often refers to the peak of the distribution in a histogram or density plot rather than a single exact value.
1
2
3
4
from scipy import stats
data = [80, 90, 85, 90, 95, 90, 92]
mode = stats.mode(data, keepdims=True)
print("Mode:", mode.mode[0])
🧭 Median
- The middle value when data is sorted
- Best used when data is skewed or has outliers
- Only works with ordinal, interval, or ratio variables
Always sort the data first, then pick the middle value (or the average of the two middle values if there is an even number of observations).
💡 Example:
For ages: [16, 17, 18, 40, 90]
Median = 18
✅ Median is not affected by extreme values because it ignores the size of extreme values at the ends of the distribution.
1
2
3
4
5
import numpy as np
data = [16, 17, 18, 40, 90]
median = np.median(data)
print("Median:", median)
➕ Mean
- The arithmetic average
- Add up all values, divide by the count
\[ \text{Mean} = \bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i \]
Where:
- ( x_i ) = each observation
- ( n ) = total number of observations
💡 Example:
Scores = [80, 85, 90]
\[ \bar{x} = \frac{80 + 85 + 90}{3} = \frac{255}{3} = 85 \]
🛑 Not ideal when there are outliers — they can distort the average.
1
2
3
4
import numpy as np
scores = [80, 85, 90]
mean = np.mean(scores)
print("Mean:", mean)
Note:
There are other means, such as the geometric mean (useful for multiplicative data or log scales) and harmonic mean (used in F1-score for classification). For most ML tasks, the arithmetic mean, median, and mode are most common.
🖼️ Visual Comparison
Here’s a quick visual to help you compare the three measures:
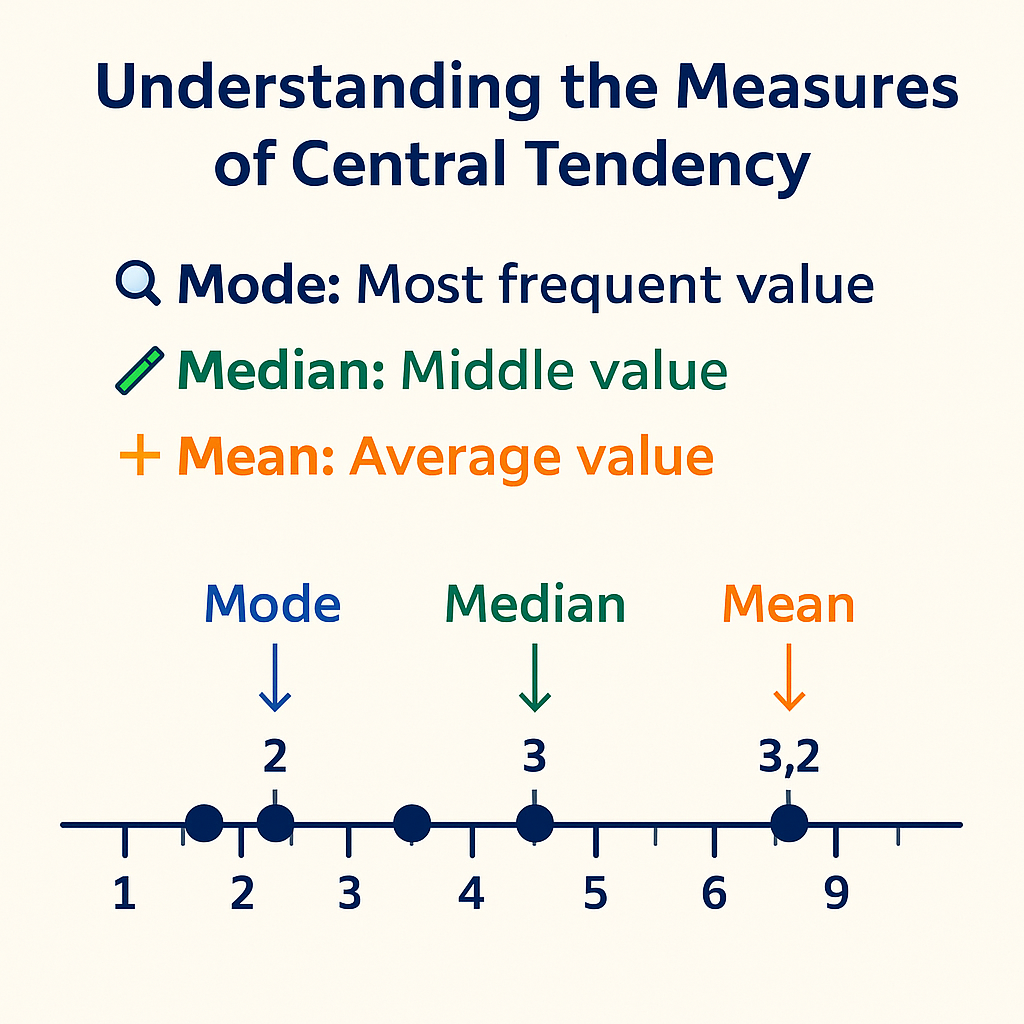
- Mode = Most frequent
- Median = Middle value
- Mean = Balances all data values
📌 Choosing the Right Measure
| Measurement Level | Mode | Median | Mean |
|---|---|---|---|
| Nominal | ✅ | ❌ | ❌ |
| Ordinal | ✅ | ✅ | ❌ |
| Interval/Ratio | ✅ | ✅ | ✅ |
⚠️ Outliers = values that are much higher or lower than the rest
👉 When outliers exist, median is often more reliable than mean.
🤖 Why Central Tendency Matters in Machine Learning
- Data Cleaning: Mean, median, or mode are often used to fill missing values in features.
- Feature Engineering: Central tendency measures summarize features for model input or reporting.
- Outlier Detection: Comparing mean and median helps spot skewed data or outliers that may affect model performance.
- Class Imbalance: The mode is used to check the most common class in classification problems.
Distribution Comparison: Comparing mean/median before and after scaling or transformation helps assess preprocessing effects.
In short, understanding mean, median, and mode is essential for preparing, analyzing, and interpreting data in any machine learning project.
👉 Real-World ML Example Table
| Scenario | Best Measure | Why |
|---|---|---|
| Filling missing values in income data | Median | Robust to outliers |
| Most common class in classification | Mode | Identifies class imbalance |
| Average pixel value in images | Mean | Used in normalization |
| Skewed housing prices | Median | Not distorted by high outliers |
📌 Try It Yourself
Q: In a neighborhood of 9 houses, 8 are priced between $300,000 and $350,000, but 1 is a mansion worth $3.5 million.
Which measure of central tendency would best describe the typical house price in this neighborhood?
💡 Show Answer
✅ Median — because it’s resistant to extreme values like the mansion.
The mean would be skewed upward by the $3.5M value, but the median stays closer to what most houses are actually worth.
Bonus: What is the only measure of central tendency suitable for categorical (non-numeric) data?
💡 Show Answer
✅ Mode — it identifies the most frequently occurring category.
For example, if most people in a survey choose “Cat” as their favorite pet, then the mode is “Cat”.
✅ Best practices for central tendency
- Match the measure to the data type. Use mode for nominal data, median for ordinal or skewed data, and mean when the variable is numeric and reasonably symmetric.
- Check for outliers and skewness. Inspect the distribution before choosing the mean; if data are heavily skewed or have extreme values, prefer the median.
- Use the mode for class imbalance. In classification tasks, use the mode to detect the majority class and quantify class imbalance.
- Combine measures for deeper insight. Compare mean and median together to detect skewness or outliers instead of relying on a single measure.
- Keep measurement levels in mind. Do not compute the mean on purely categorical labels and be cautious when averaging arbitrary codes or ranks.
⚠️ Common pitfalls with central tendency
- Using mean with skewed or outlier heavy data. When the distribution is strongly skewed or has extreme values, the mean can be pulled away from the bulk of the data; in such cases the median is usually more robust.
- Using mean or median for categorical data. For purely nominal categories, neither mean nor median is meaningful; use the mode instead.
- Ignoring multiple modes. Multi modal data can have more than one mode, so reporting a single "most common" value can be misleading.
- Forgetting to sort before finding the median. If the data are not sorted, the "middle" element in the list is not the statistical median.
- Assuming the mean is always typical. In skewed distributions, the mean can lie in a region where few observations actually occur, so it may not represent a typical case.
🧠 Level Up: When and Why to Choose Mode, Median, or Mean
Each measure of center has its strengths depending on the data and the question:
- 📌 Mode is great for identifying the most common category or value — useful in marketing, survey analysis, and categorical data.
- 📌 Median provides a robust center when your data has outliers or is skewed — like income or house prices.
- 📌 Mean is ideal when data is symmetrically distributed and you want to use all values — common in scientific measurements and many ML algorithms.
Knowing when to use each makes your analysis more accurate and meaningful.
🔁 Summary
| Measure | Best For | Sensitive to Outliers? |
|---|---|---|
| Mode | Nominal, any variable | ❌ No |
| Median | Skewed/Ordinal data | ❌ No |
| Mean | Symmetrical data only | ✅ Yes |
✅ Up Next
In the next post, we’ll talk about how spread out your data is.
That’s called Measures of Dispersion — including Range, Interquartile Range, and the Box Plot.
Stay curious!
📺 Explore the Channel

🎥 Hoda Osama AI
Learn statistics and machine learning concepts step by step with visuals and real examples.
💬 Got a Question?
Leave a comment or open an issue on GitHub — I love connecting with other learners and builders. 🔁