Understanding Microsoft Semantic Kernel: Core Concepts
A deep dive into the core concepts behind Microsoft Semantic Kernel, explaining how Kernel, Plugins, Memory, and Orchestration work together to move from prompt-based AI to production-grade AI systems.
🧠 Why Core Concepts Matter
Before we talk about components, we need to reframe how we think about Semantic Kernel.
It is not just an SDK.
It is an AI architecture layer that sits between:
- ● Large Language Models
- ● Application logic
- ● External systems and tools
At first glance, prompt-based applications feel enough.
You send a prompt → get a response → build a feature around it.
But this breaks quickly in real systems:
- ●Logic becomes scattered inside prompts
- ●No clear separation between reasoning and execution
- ●Hard to reuse or scale behaviors across features
This is where architecture starts to matter more than prompting.
And this is exactly where Semantic Kernel becomes important.
💡 Key Insight
Semantic Kernel is not about making LLMs smarter.
It is about making AI systems composable, controllable, and scalable.
📘 What You’ll Learn
- ● What the Kernel actually does in an AI system
- ● How AI Services connect models like Azure OpenAI and OpenAI
- ● Why Plugins represent capabilities, not just tools
- ● How Memory extends context beyond chat history into knowledge
- ● What orchestration means at the system design level
- ● How these components combine to build production-ready AI workflows
🧩 The Kernel: The Coordination Layer
At the center of Semantic Kernel sits the Kernel — the central orchestration component of the system.
But calling it “the core object” is misleading.
A better mental model is:
The Kernel is an orchestration brain, not a runtime engine.
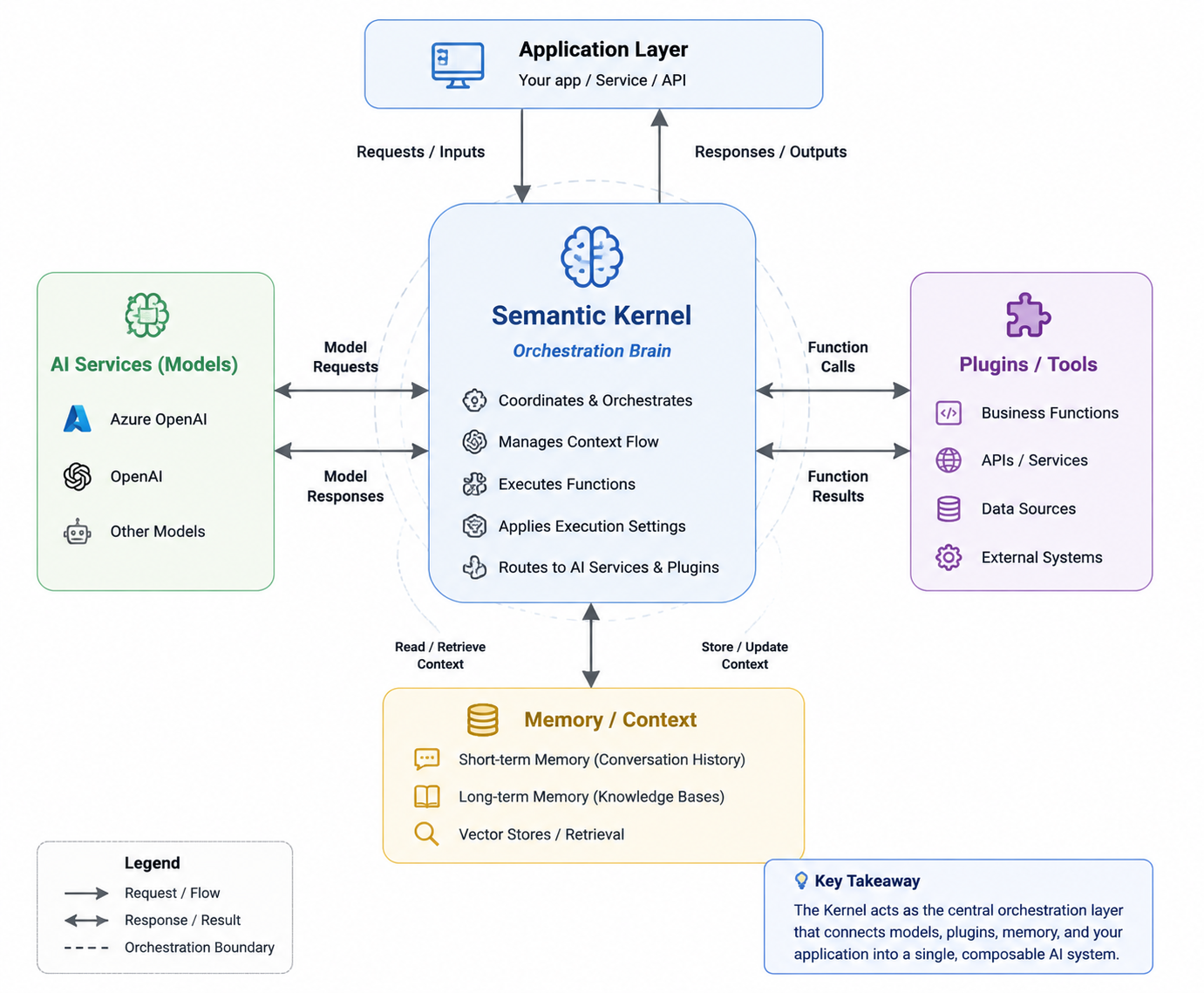
It acts as the coordination layer between:
- ● Model calls
- ● Function execution
- ● Plugin invocation
- ● Context flow
- ● Execution settings
Instead of your application directly calling an LLM, everything flows through the Kernel.
This is what enables a key architectural shift:
From isolated AI calls → to managed AI workflows
⚙️ Why This Matters
This design creates a critical architectural advantage:
| Without Kernel | With Kernel |
|---|---|
| Direct prompt calls | Structured orchestration |
| Tight coupling to model | Model abstraction |
| No reusable logic | Composable functions |
| Hard to scale workflows | Workflow-driven AI |
The key difference is not technical complexity — it is control and composition.
Without orchestration, AI behavior is fragmented.
With Kernel, AI behavior becomes system-defined.
🔌 AI Services: Connecting to Models
In traditional AI applications, the code is tightly coupled to a specific model provider.
You write logic that directly depends on:
- ● OpenAI APIs
- ● Azure OpenAI endpoints
- ● Or any other LLM provider
This creates a hidden problem: your architecture becomes model-dependent.
Semantic Kernel introduces a different abstraction.
AI Services act as a decoupling layer between your application and the underlying model provider.
This includes:
- ● OpenAI-compatible APIs
- ● Azure-hosted models
- ● Custom LLM endpoints
But the important idea is not the provider.
It is abstraction.
Instead of writing model-specific logic, you define intent, not implementation:
- ● “I need reasoning capability”
- ● “I need summarization”
- ● “I need classification”
And the Kernel resolves this intent to the appropriate configured model.
This shifts the design from:
Model-driven architecture
to:
Capability-driven architecture
This makes swapping models an architectural decision, not a code rewrite.
🧠 Plugins and Functions: Giving AI Capabilities
This is where Semantic Kernel starts to shift from a language model wrapper into a real application architecture.
Large Language Models alone are powerful at reasoning, but they cannot reliably:
- ● Query databases
- ● Execute business logic
- ● Call external APIs
- ● Perform deterministic computations
This creates a clear architectural gap.
To bridge this gap, we introduce Plugins.
A Plugin is a modular capability boundary that groups related functionality into a structured unit.
Inside each Plugin are Functions, which represent atomic units of execution.
Examples of Functions include:
- ● Calculate revenue gap
- ● Retrieve customer records
- ● Send email summaries
- ● Trigger workflow approvals
Think of it like this:
| Concept | Meaning |
|---|---|
| Plugin | Capability domain / boundary |
| Function | Executable unit of work |
| Kernel | Runtime orchestration layer |
This design is what enables a fundamental shift:
from conversational AI → executable AI systems
🧠 Memory: Context Beyond Chat History
Large Language Models are inherently stateless.
Each interaction is independent, with no built-in understanding of:
- ● past interactions
- ● domain-specific knowledge
- ● long-term user or system context
This is where the concept of Memory becomes essential.
Memory is often misunderstood.
It is NOT just chat history.
Instead, it is a contextual retrieval layer that enables systems to ground responses in relevant information beyond the current prompt.
It allows the system to:
- ● Store structured knowledge
- ● Retrieve relevant context dynamically
- ● Maintain long-term contextual understanding
This capability enables:
- ● Personalized AI experiences
- ● Knowledge-grounded responses
- ● Enterprise-grade AI assistants
Memory shifts the system from:
“What did we just say?”
into:
“What context is relevant to solve this problem correctly?”
⚙️ Orchestration: The Real Value
If there is one concept that defines Semantic Kernel as a system, it is this:
Orchestration is what transforms LLMs into systems.
Large Language Models on their own are:
- ● non-deterministic
- ● stateless across tasks
- ● and lack structured execution flow
Without orchestration:
- You have isolated prompts with no coordination
With orchestration:
- You have structured, multi-step workflows
These workflows allow the system to:
- ● Chain multiple functions
- ● Combine reasoning with tool execution
- ● Enforce execution order
- ● Introduce control flow logic
This is what makes AI systems predictable and reliable enough for production environments.
🧠 Architecture Insight
- The model handles reasoning
- Plugins handle execution
- Kernel handles orchestration
- Memory handles context
🚀 Key Takeaways
- ● Semantic Kernel is an architecture layer, not just a library
- ● Kernel = orchestration center, not model wrapper
- ● Plugins convert AI from text generator → action system
- ● Memory is a context intelligence layer, not chat history
- ● Orchestration is what enables production-grade AI systems
🔭 What’s Next
In the next article, we’ll move from concepts to architecture patterns:
We will explore:
- Prompt-only systems
- Tool-enabled AI systems
- Memory-driven architectures
- Fully orchestrated workflows
And how each one represents a different maturity level in AI engineering.
📚 Official Microsoft Resources
For deeper technical context and implementation details, refer to the official Microsoft documentation: